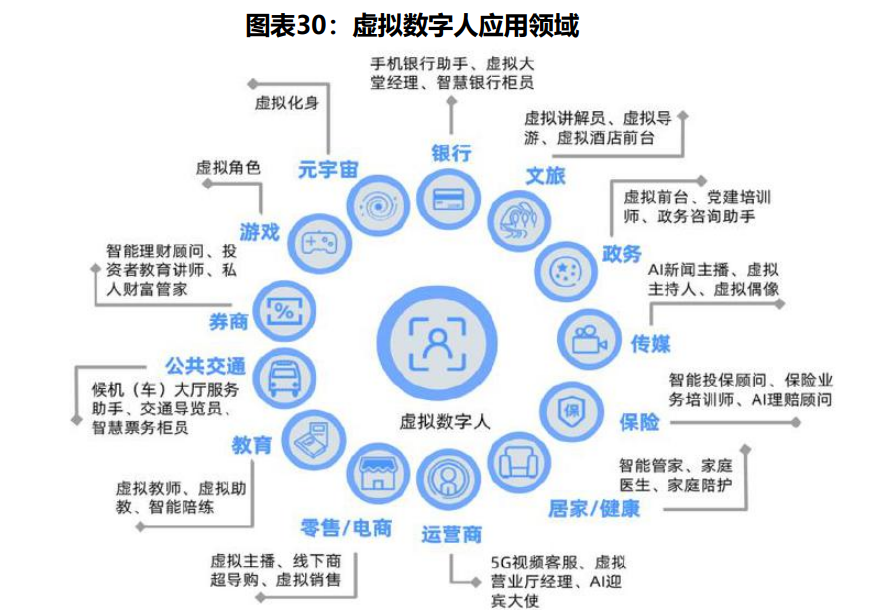
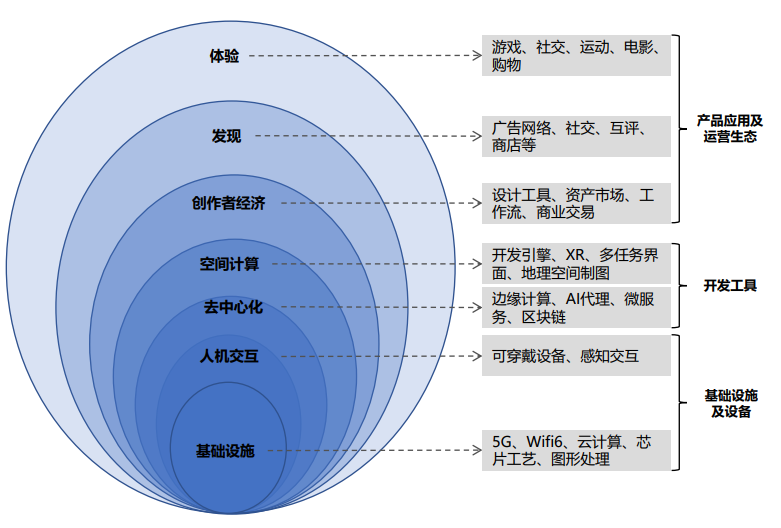
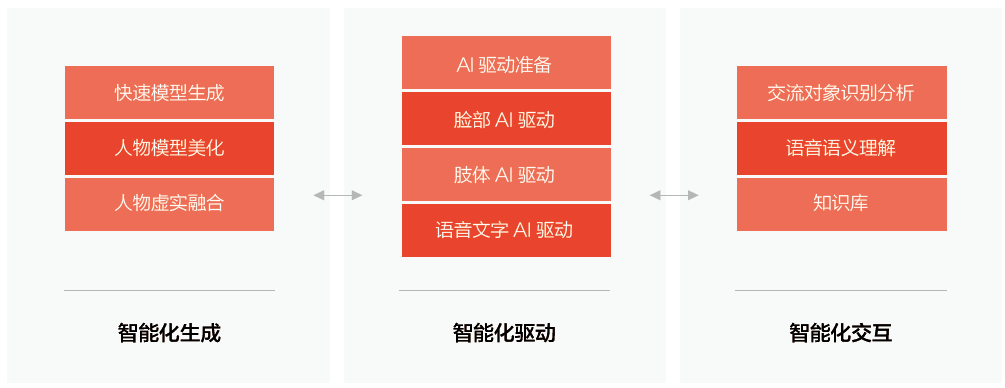
虚拟数字人是一项融合了先进技术的创新成果,根据其是否具备交互模块,可划分为交互型虚拟数字人和非交互型虚拟数字人。在交互型虚拟数字人中,又可进一步分为AI驱动型和真人驱动型。
交互型虚拟数字人是一类具备与用户互动能力的数字化实体。在这一类别中,AI驱动型虚拟数字人通过智能系统自动解析外界输入信息,根据解析结果决策数字人后续的输出文本,并通过人物模型生成相应的语音与动作,从而实现与用户的高度互动。这种虚拟数字人能够自主地接收、理解和回应用户的信息,为用户提供更为智能和自然的体验。
真人驱动型虚拟数字人采用真实人物的输入来驱动。通过视频监控系统传来的用户视频和实时语音,结合动作捕捉采集系统,真人的表情、动作能够准确地呈现在虚拟数字人形象中。这种交互方式不仅实现了数字人与用户的面对面交流,还使得虚拟数字人能够模仿真实世界中的人类行为和表情,进一步提高了交互的真实感和情感表达。
在另一方面,非交互型虚拟数字人则主要侧重于任务执行而非与用户的实时互动。这类虚拟数字人不具备交互模块,系统根据预定的目标文本生成对应的任务语音及动画,然后合成音视频呈现给用户。尽管不支持实时交互,但这种类型的虚拟数字人在某些场景中仍具有广泛的应用价值,尤其是在需要自动化执行任务或提供信息展示的情境下。
虚拟数字人的分类体系清晰而全面,涵盖了多种应用场景。交互型虚拟数字人通过AI或真人驱动,实现了与用户更为深入的互动,而非交互型虚拟数字人则在特定任务和展示需求中发挥着独特的作用。这一多元化的发展方向为虚拟数字人技术的不断创新提供了广阔的空间,将进一步推动数字技术与人机交互的融合,为未来数字化社会带来更多可能。